



Using AI for Rapid Sense Making in Workshops
An experiment in trying to stay in a tight budget using AI tools for research and synthesis

TL;DR: There’s an audio embed below with an AI generated podcast explaining all this.
Yesterday I wrapped up a workshop with an NGO here in Toronto. Normally I would show up with a team to support 30 people going through a two-day process, but while the budget was too small to bring a team, the cause was too good not to support.
However, the session was high-stakes for the NGO and the subject was technical, requiring a lot of detail and synthesis. I decided to try and use a few AI tools in the process to see if I could still deliver the synthesis and analysis throughout the process without a team to help. As some of you may have read, I already had AI on my mind this week after a surprising introduction to NotebookLM, and so I was in an experimental mood.
There were a few problems I was trying to solve for. First, for inputs, there were a few instances where the participants needed some structured research to guide their thinking, and this normally takes a lot of time and work to prepare. Second, and more importantly, one of the key elements of accelerated iterative design work is the ability to harvest insights from previous iterations (earlier rounds of work) in order to do the next iteration, and this is often a key function of a support team - capturing, synthesizing and presenting key elements in realtime so the group can keep refining.
A key piece of context on how I run workshops that might help this make sense: participant work is designed backwards from the desired outcomes and broken into modules of work, which start with broad lateral thinking exercises to align on assumptions and narrowing through each iteration - which is done in parallel teams - towards a unified product. This requires a ton of information processing in order to allow a bunch of inputs on sticky notes, flip charts and whiteboards to cohere into something at the end that reflects the diversity of inputs through each round.
Here’s where the tools augmented the process best.
Research and Preparing Inputs
This group was going to be mapping the donor journey in order to smooth the process, understand any friction points and make donors feel more connected with the impact of their contributions, so I wanted them to first think about that experience through the lens of other organizations - in this case companies - that have used a lot of research and data to shape their customer experience.
In the workshop, this is a quick exercise, so they need enough information about these different companies to take on that perspective, without spending too much of their time sifting though material to figure out what makes that company tick.
I would normally collect a range of articles that could be available to each of the teams to go through if they had a lot of time, or prepare a synthesized version highlighting the key elements of each organization to guide their thinking. This can be a lot of work, especially as we were talking about 5 different companies: Spotify, Apple, Amazon, Tesla and Disney (theme parks).
I opted to use Perplexity to speed up this process. I worry about using a generic LLM like ChatGPT for a task like this because of the risk of hallucination (the model just “making up” answers) which would require me to spend time fact checking all the outputs. Perplexity is good for structured answers to research questions, and is doubly good because it provides sources along with its outputs, so it can also be a good way of finding primary sources as well.
Using simple prompts like “how did amazon transform the customer experience for online shopping” and “how does apple create a unique customer and user experience” I was able to get a pretty decent summary of the key highlights of each company’s approach. You can take a look at the results here.
An important caveat - I really don’t like the idea of using AI to generate material you want to pass off as a final product or definitive summary. Some of the sources are LinkedIn articles and blogs, for example, which, while I was happy with the answers, don’t really rise to the bar of a citation you might use in a formal study. As input to an ideation process, however? I was comfortable with the risk on the materials not being definitive, as it just needed to be “good enough”.
The results? Let’s say it would have taken me about 45 minutes to research and compile good material on each company, and, if I was to do a summary, maybe another 30-45 minutes on a write-up for each company. For 5 companies, that would mean spending between 6 to 7.5 hours to prepare that research for just one exercise in the workshop. Instead, this took about 30 minutes, which was largely spent just reformatting the output in a printable document so it didn’t look all weird.
Summarizing Team Outputs in Realtime
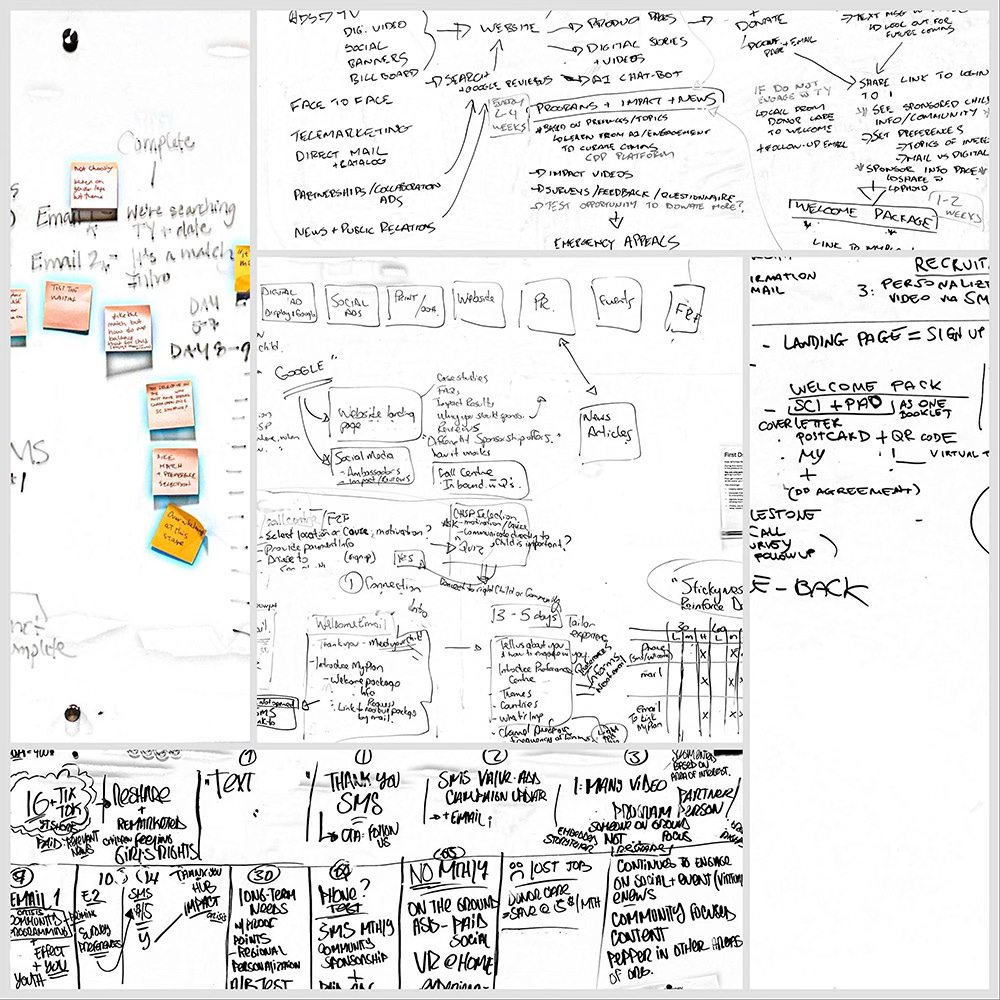
Over the course of the two days, went through eight rounds of work, 6 of which had intensive outputs. Outputs came in the form of work on sticky notes, hand-filled templates, whiteboards and flip charts. They created personas, drafted end-to-end journey maps of the donor experience and developed hypotheses and tests to address issues across the entire donor experience.
In a workshop setting, you try and mitigate some of the information loss between rounds of work by having teams do a small synthesis at the end of each round, but invariably they get tired of the extra capture and a lot gets left behind on the boards. Also, quite a lot is said when they report out to other teams that is difficult to capture in the moment, and even more difficult, after the fact, to reconcile with what they had scratched on their whiteboards.
I tried a few different tools to wrangle this information - again, because I was alone running this workshop, and was at the same time picking up coffee cups and resetting chairs.
In order to use any of the AI tools to help sense making, I needed as much of the analog work they were doing to be machine-readable as possible.
Team Report Outs: I used the Voice Memos app on an iPad to record each explanation by the teams of their work, creating a separate recording for each individual team (and naming each file after the topic being reported). With the latest iOS update, voice memos automatically generate a written transcript.
Whiteboards and Flipcharts: I used TurboScan on my iPhone (you can use CamScanner, or any number of other capture apps) to capture the outputs of each team, saving each one into a PDF named for the topic they were working on.
With all of that captured, I wanted to make rapid summaries that could help them see important points in their work from each round.
For this, I decided to put Google’s new NotebookLM through its paces. For each round of work, I uploaded the PDFs of all the whiteboard images and raw audio files and generated a “Briefing Document” based on that input.
The summaries were shockingly good. I wasn’t sure if NotebookLM could do handwriting recognition or not, and I can confirm that not only can it recognize handwriting, but it seems to be able to interpret the connections and relationships between chunks of information based on how the material is written on the board. For example, it was able to discern, just from the images, that the personas were personas, and therefore the written text represented attributes of those personas, and that the boxes on the journey maps represented stages of a donor journey.
One major observation here, though. It occurred to me after the fact that maybe the reason it was so good at figure that context out was that in some of the images, the written assignment instructions I had given the teams were visible. I tested this assumption by going back into the images and erasing the assignments and re-running the material through NotebookLM. The AI was actually still able to infer the context of what the images were (surprisingly), however, what I noticed when I generated the briefing document was that the output was much more brief and much less nuanced, so it appears that giving it the extra context for what it is looking at has a pretty significant effect on its ability to make sense of the rest of the information.
I generated one of these briefing documents after each round of work, so that as an input for the next round of work, participants had a handy summary of the salient ideas explored across all of the teams earlier in the process, which meant that I was now able to have a self-synthesizing process in pretty much realtime without any other support (though, realistically, some support would have been great, because it meant I didn’t have time to eat, drink or sit down).
A fun output from each of the NotebookLM compilations was also a “podcast” - a dialogue between two people (currently in English only) doing a “deep dive” on the material for each round. Their summaries were surprisingly good, and made the information very digestible. I played some of these summaries during the breaks over the house speakers as a reinforcement of some of the themes, and uploaded them all to the group’s Microsoft Teams space as well. As an example, here is this post run through NotebookLM in podcast form:
It also meant that by the end of the day, before I walked out of the room, there were extensive, detailed written summaries of all the work the groups had done. Even with a person on site dedicated to producing that, it would have been difficult to turn around in between rounds of work, and by the end of the day, would likely be, at best, in the form of raw notes, not something edited and synthesized. Instead of squinting at flip charts today, I was able to write this post. Which means saving 10 person-hours of a documenter on-site, plus probably a half-day of summarizing after the fact.
All told, then, the experiment allowed me to still support the group pretty well on my own, and saving a total of at least 20 person-hours of work. Not bad.