

Solving AI's Security and Compliance Problems
For when you want to use AI, but you're not allowed cloud services


I would alternately call this the “CoPilot Problem” in consulting. You want to use AI as a part of your workflow for processing information as part of a project, but either your own company or your client insists that the only AI that is allowed is CoPilot. Which, of course, is the immediate death of being able to do anything interesting with AI.
Having run into this problem repeatedly, I found myself in the awkward position of having completely convinced myself of the utility of using AI, but now being in environments where I was unable to use it.
This, in my view, is a huge hindrance in AI adoption, as there is so much friction in being able to experiment, that workflows remain stuck in the past. For those working with sensitive or confidential data, who have specific compliance requirements or are in client service work, it is hard to justify the time and investment required to modernize your workflow or experiment with AI if you will not be able to use any of the tools for a significant portion of your work.
For anyone who has been reading this Substack, you’re probably aware that I’ve been using AI for some of my more basic workflows, but in ways that I have become reliant on. Working on projects where AI isn’t an option suddenly feels like I’m being asked not to use any electricity - it’s certainly possible, but it seems unnecessarily cumbersome.
I began experimenting with alternative solutions to see what might be possible with different types of automation and processing if I created some solutions that were not reliant on any type of cloud service or would not require the transmission of data “out of the room”. This has felt an added sense of urgency with the worsening trade disputes and tariff wars, as it seemed increasingly unwise to become even more reliant on technology that could be “switched off” or tariffed as part of ongoing tensions. So part of this has been a practicality of client work in restrictive IT environments, and part of it has been an experiment in creating a more sovereign tech stack.
What I have found is that for most of the simple use-cases that are used in a project setting, or as part of a collaborative process, you can achieve the same or better results as most cloud AI services, so long as you have the right hardware setup. During the last few months, I’ve gone through 10 hardware prototypes and 15-20 software prototypes to land on something that met my requirements, and I’m pretty pleased with the results.
What I needed was the ability to run some basic AI workloads in any environment I might find myself - let’s say, in a hotel ballroom with little to no internet connectivity, in a place I had to travel by air to get to, with a group of people working on highly confidential material and absolute restrictions on the use of any cloud services.
Within that environment, I would still like to be able to:
process audio recordings into high quality transcripts in realtime or near-realtime
summarize large quantities of text data
generate code for various automation tasks throughout the process
execute computer-vision tasks such as image-to-text
The good news is that I found the availability of open-sourced models to be of very high quality, meaning that what is available out there to be run on your own hardware is absolutely capable of these relatively simple AI jobs.
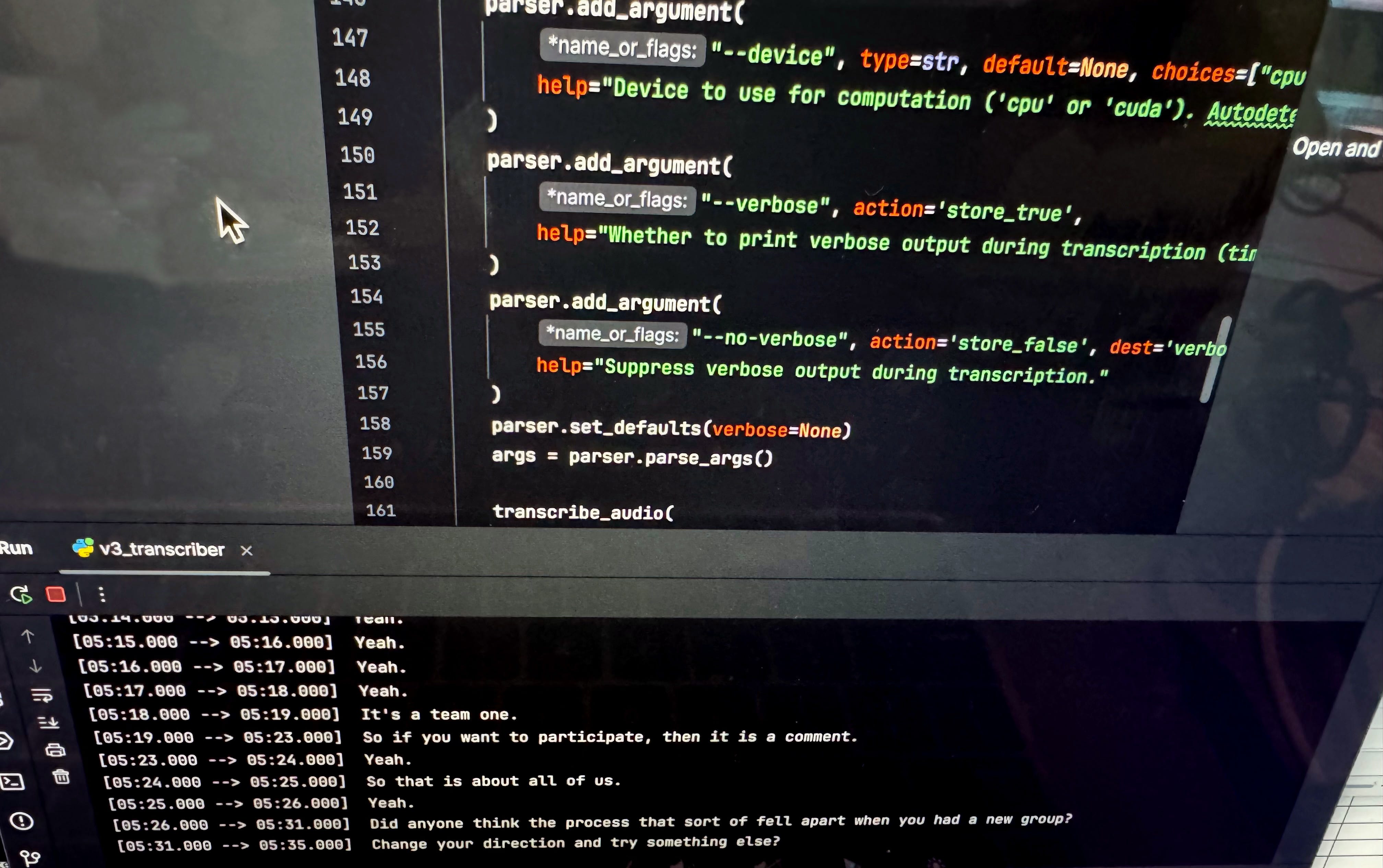
The challenge was in finding what the minimal hardware required would be that would make them workable and fast enough to be useful. My first prototypes using “edge” hardware (small, low-power, low-cost devices) was really cool, but not able to produce useful results. In the image above, you can see repetitive text coming up in the transcript (“Yeah. Yeah. Yeah. Yeah”) which is something that comes up with the smaller models required to run on less powerful hardware. I had envisioned a bunch of cheap little boxes that could be whipped out to do all the work required, and while I was impressed with what they could do, it wasn’t enough.
Taking me back to the early pandemic when I was building gaming computers with my kids, it became very clear why Nvidia’s stock has been doing so well: AI really likes to run on big, fat graphics cards.
While this is changing, it’s not changing fast enough, so where I landed for the current build is the requirement for what is, essentially, a high-powered gaming computer that you can put in an overhead bin on an airplane.

The result is this little guy. It’s built into a small Pelican case, and has all the power needed to run some pretty heavy workloads, without breaking the bank. While I could make a much more powerful one, my goal was to make something as cheap as possible while still meeting the requirements (the cost of materials was around $1500 CAD).
In a way, it feels like a bit of a throwback; we’re back to needing powerful hardware instead of sending everything “to the cloud”, but the trade-off is worth it. The results it returns are amazing, there are no cloud fees, no problems if there is patchy internet and you don’t have to secretly wonder if you’ve missed something important in the Terms of Service that might end up compromising a bunch of client information in some way that will come back to haunt you.
What it means for me is that I can now more confidently rely on standardizing my own work process, without having to worry that depending on the client or the project I will have to figure something out from scratch to comply with whatever their policies might be. And if I show up and, as usual, the internet connection we’d been promised is barely above late 90’s dial-up, I can still run everything I need.
Which is great, because I’m convinced that my next prototype doesn’t just change how to support decision-making, it will change the process of decision-making itself.